
Why data is the most undervalued element of AI development
A recent survey by Google Research reports that while the performance, fairness, robustness, safety, and scalability of AI systems mainly depend on data, data is the most undervalued and underappreciated element of AI development. In high-stakes domains (domains that have safety impacts on living beings, e.g. road safety, credit assessment), 92% of AI practitioners report that they experience so-called Data Cascades – compounding events causing negative, downstream effects from data issues, resulting in technical debt[1]
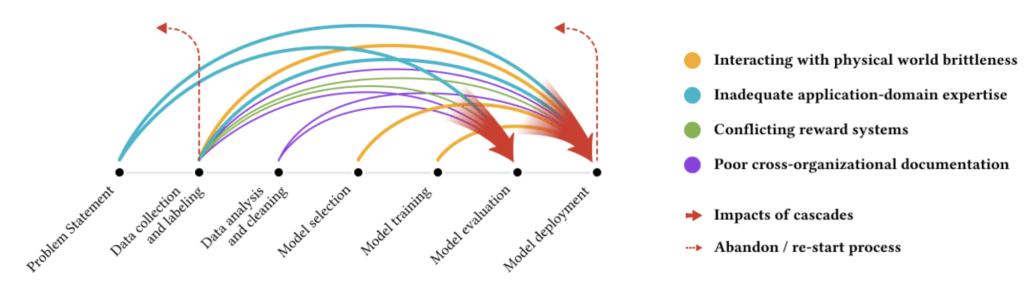
Data cascades
Data cascades arise from data issues and have complex long-term effects, which occur frequently and persistently. They are characterized as opaque, having no clear indicators, tools, or metrics to detect their effects. Data cascades are frequently triggered in upstream data collection, and negatively impact downstream model evaluation and deployment. For example, in eye disease detection, a machine learning model can be trained on noise-free data and high performance. In production it fails to predict the disease due to dust on images.
Now, to make sure you don’t suffer from data cascades, it is important to maintain high-quality data. But what do we mean when we talk about ‘high-quality data’? And how do we determine data quality? To answer these questions we will look at the definition of data quality, qualitatively as well as quantitatively. Afterward, we will explore common causes of low data quality and what to do to be more data-driven without the best data quality.
What is Data Quality?
According to the Data Management Body of Knowledge (DAMA-DMBOK), a guide that aims to provide a general framework for data management:
“The term data quality refers to both the characteristics associated with high-quality data and to the processes used to measure or improve the quality of data.”
In this definition, we find a qualitative and a quantitative feature of data quality. One we can describe and one we can measure. We will go through both parts to define what data quality is.
Qualitative feature
“Data is of high-quality to the degree that it meets the expectations and needs of data consumers. That is if the data is fit for the purposes to which they want to apply it. It is of low quality if it is not fit for those purposes. Data quality is thus dependent on context and on the needs of the data consumer.”(DAMA-DMBOK)
Data quality is related to a certain purpose, the needs of data consumers (within or outside a company). The purposes aren’t always clearly defined, and people that manage the data or its consumers often don’t articulate their needs. Defining the needs of data consumers and staying up to date about these requirements is key in maintaining data quality. Begs the question: how can we measure data quality?
Quantitative feature
To measure data quality, we can divide data quality into dimensions. Dimensions that are both important to business processes and measurable. In DAMA-DMBOK we find numerous dimensions, of which we will highlight some here:
- Accuracy
Does the data sufficiently represent reality? This is hard to define precisely and hard to measure without going through data manually. Therefore, it is often best to compare samples of the data to a verified data source. - Completeness
Is all the data that I need present? There can be mandatory features that require values in each row, or optional features that don’t. Here we can compare samples of data over time and see if the data is populated correctly over time, or compare samples to a verified source. - Consistency
Is data consistently represented? Is the same file type and name used over time? Do we see data represented the same way at different sources? To measure the consistency of the data, we can look at the same records from different sources of data, or compare records at different points in time.
Data is of high-quality if it matches the expectations and needs of data consumers. Based on these expectations and needs, we can determine to what extent the data must conform to each separate dimension. Moreover, while it might feel as if these dimensions overlap, it is important to score the data quality on each separate dimension. So, the accuracy is merely about how well the data represents reality. In the dimension of completeness we are looking at how many records have missing values.
Causes of low data quality
As we saw earlier, data is the most undervalued and underappreciated element of AI development. There are numerous causes for low data quality, such as,
- Lack of awareness/education: More often than not, graduate AI courses are focused on tuning the best algorithm on well-cleaned and prepared datasets (e.g. Kaggle, UCI Census data), while in practice we almost never see clean data. The more glamorous part of AI is model development. Data is seen as ‘operations’.
- Lack of incentive: When it comes to data quality, it can be unclear what the long-term consequences of low data quality are. A clear incentive to maintain high-quality data might be absent, which makes it harder to get a budget for data management.
- Lack of accountability: It can seem as if no one is responsible for data quality since the structure of an organization often does not include a dedicated data manager type of role. Everyone is responsible for ‘their’ part of the data lifecycle, which makes no one accountable, negatively impacting data quality in the long term.
- No clear-defined metrics: AI practitioners mostly use metrics to determine the goodness of fit of the model to the data, rather than metrics for determining the ‘goodness-of-data’.
- There is a limited set of tools/frameworks to determine data quality: current inspections and analysis tools are focused on data wrangling and measuring data distributions while determining dataset requirements beforehand and monitoring new incoming data in production often does not get sufficient attention.
What to do in case of poor data quality?
Reading about the definitions of data quality and all the possible causes of poor data quality might make you reconsider your data-driven use case. However, it can be very useful to start with a simple and small use case. It could be the case that certain departments within your organization have their data quality in order, better than other departments. Furthermore, implementing a data-driven solution does not have to be a state-of-the-art system with the best performance from day 1. Starting with dashboarding to provide useful insights can be a good starting point to see the value of having decent data quality, which can then trigger your organization to improve it.
Data quality is always related to a certain purpose so starting with a use case shows where the data quality still lacks and provides clear steps about what needs to be improved.
Conclusion
In this blog, we have looked at what data quality is, qualitatively as well as quantitatively, and how dividing data quality into different dimensions can help in determining the overall quality. We saw that data is of high-quality if it meets the needs and expectations of data consumers. We can divide data quality into different dimensions, through which we can measure the overall quality. There are also different causes of low data quality and potential consequences upstream data issues have in AI systems. Data is the most undervalued and underappreciated element of AI development, while it can have huge consequences on the functioning of AI systems.
[1] Technical debt is a metaphor used in software engineering to represent the accumulation of cruft (internal quality flaws) in software systems as debt accrual, comparable to financial debt.
Used sources:
Evans, Nina & Price, James. (2012). Barriers to the Effective Deployment of Information Assets: An Executive Management Perspective. Interdisciplinary Journal of Information, Knowledge, and Management.
Sambasivan, N., Kapania, S., Highfill, H., Akrnog, D., Mois Ayoro, L., (2021). Everyone wants to do the model work, not the data work”: Data Cascades in High-Stakes AI. SIGCHI, ACM
From Big Data to Good Data with Andrew Ng (2021)
EARLEY, S., & HENDERSON, D. (2017). DAMA-DMBOK: data management body of knowledge.
Please fill in your e-mail and we'll update you when we have new content!
 Check out our Meetup group!
Check out our Meetup group!