
Successfully adopting AI in the world of Dutch libraries
Full digitization of products and processes is and will be an important focus point of many large SMEs and mid-corps. Also, within digitization, data and ML play a key role. For the past 2 years, we have been working with NBD Biblion an organization that selects and distributes books to most of the public libraries in the Netherlands. Together with several other external parties (responsible for mainly front-end and UX), Enjins developed the Machine Learning-driven ordering advice engine. This engine now enables NBD Biblion to serve its customers (libraries) with automated weekly ordering advice. In this article, we share our learnings of adopting AI in the world of Dutch libraries. It shows that involving the field experts is crucial to get your ML solutions adopted and create business impact.
NBD Biblion and the book selection process
NBD Biblion provides support to libraries in their core business: central buying, binding, cataloging and getting books ready for the public library. In doing so, NBD Biblion provides libraries with a personalized list of books that are recommended to buy every week, the result of the “selection process”. While considering the social function of libraries by having a broad collection, NBD Biblion needs to match the expectations of each unique library and their unique visitors with a relevant collection in libraries. Before our collaboration, this process used to be a time-consuming and manual process. Moreover, only the collection experts knew which books would fit best in the libraries. Therefore, the process was hard to scale to new libraries. Above all, for the organization, it is all about finding the balance between having a broad collection and a popularity-based collection.
The dot on the horizon: the ML-driven ordering advice engine
Enjins and NBD Biblion started their cooperation in 2018 with a clear dot on the horizon: realize full digitization of the selection process, with data and ML-driven decisions. The aim was clear: NBD Biblion wished to scale their service to most of the Dutch libraries. For this, many inputs needed to be processed to create a collection optimized for every library (i.e. library-specific wishes, library budgets, changing reading demand of consumers, region-specific demand). NBD Biblion had the conviction that new technologies like ML would be the key to work towards this “dot on the horizon”.
Our solution: the ML-driven ordering advice engine integrated into the digital channel of NBD Biblion
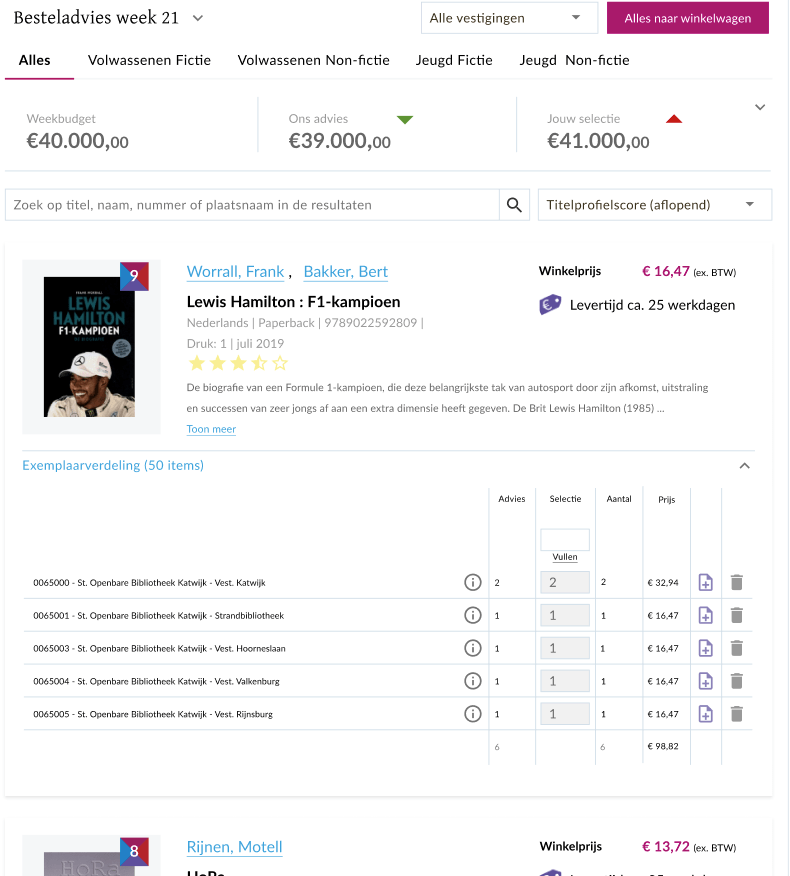
To optimize their ordering advice process for libraries, we developed an engine to generate a library-specific ordering advice based on demand, supply and the preferences of the library. This Machine Learning driven ordering advice is visible on the webshop. There, the ordering advice can be modified, and the books can be purchased. The library itself can do the selection, or with the help of a selection service employee. Together with another partner of NBD Biblion, Online Department, we created the design of the ordering advice on the webshop. We made it in the most suitable and easy way to use for the selection service employees as well as for the libraries. As a result, by monitoring what libraries will actually order, the engine gets valuable feedback on its recommendations and can further optimize its results.
The intelligence behind the ML engine
We built the Machine Learning driven ordering advice in roughly three parts:
- Different data pipelines handle the collection and transformation of the inputs needed to generate the ordering advice. For instance, the inputs are library preferences and budget; book titles to choose from, including information about each book; and demand based on library collection and transaction data.
- Based on the input, the engine generates the ordering advice. Beforehand, libraries have set their requirements. If the books do not meet the requirements, the system will filter then them out. After this, from the eligible books, the engine selects some of them that will be in the ordering advice for the library. Also, the engine determines the number of books to select of each title and how to distribute certain books over multiple libraries of an organization.
- The engine sends the ordering advice to the webshop. Every night, the system generates a new ordering advice based on that week’s book titles. As a result, the webshop can then order the new selection.
Below, we shared a schematic overview of the process flow.
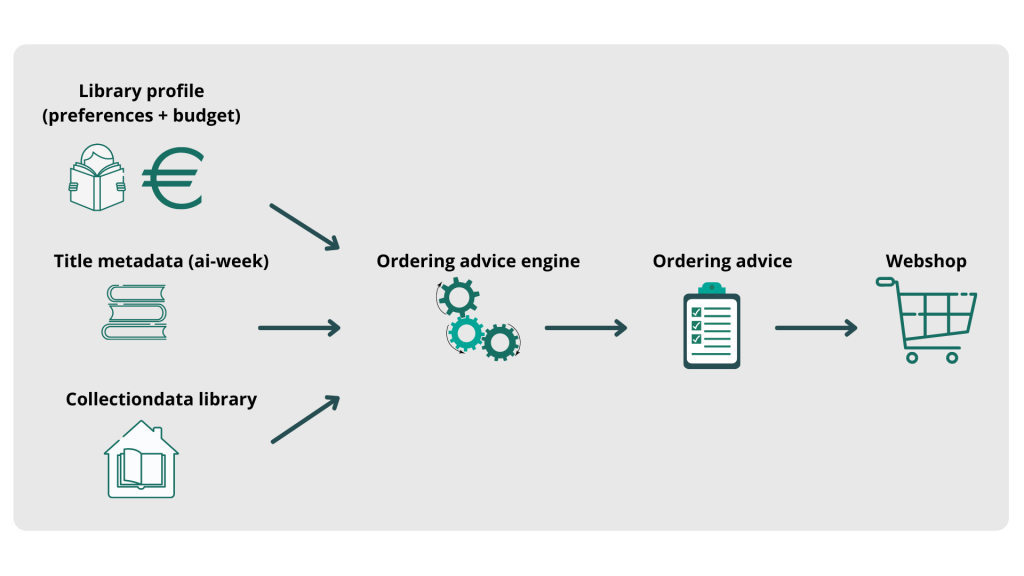
Image 1: Dataflow from library profile, title metadata and collection data to ordering advice in webshop.
The roadmap towards the ML-driven ordering advice engine in six steps
- Setup of analytics environment. We daily loaded several sources (ERP, CRM, library inputs) into a newly developed central analytics environment where data is readily available for analysis.
- Library benchmarking dashboard. To better understand current collections and decisions made, we gained insights into collections by conducting analyses and benchmarking libraries.
- Developing the ordering advice engine. Once we gathered descriptive insights, AI development started. By developing an engine to generate library-specific ordering advice based on demand and supply and the preferences of the library, we met two objectives:
- Optimal collection in the library. On a weekly basis, the engine will generate library-specific ordering advice that optimizes the collection of the library.
- By automating some steps in the book selection process, NBD Biblion can serve more libraries with data-driven ordering advice.
- Testing the engine in-house with selection experts. Developing an ordering advice engine is all about understanding the work process of the selection service employees. They know which criteria and themes are important to libraries and how these criteria and themes can differ between libraries. For example, some libraries focus on having a broad selection of books in foreign languages such as Polish, Turkish or Italian, whereas other libraries will have stronger preferences for religious books. This often depends on the region, the institutional mission and/or the demography. Therefore, we worked closely together with experts while developing the ordering advice engine. After every major release of additional features, we evaluated the results together with the experts. This analysis gave us further insights into their work-and-think process. As a result, we used their feedback to optimize the ordering advice engine further.
- Integration in the NBD Biblion webshop. After successful in-house testing, we integrated the engine into the NBD Biblion webshop. Both employees of NBD Biblion and pilot customers can see the ordering advice and overrule their orders if they want. This valuable feedback loop is used to improve the engine.
- Scale to all libraries. Finally, the last step was to make the engine available for all libraries that NBD Biblion serves. By automating the selection process, we could scale it to all libraries without the need of hiring more selection service employees.
Technology used
To realize a scalable and future-proof solution, we built the engine in Python and containerized it using Docker. The data pipelines that are used to extract, transform and load data from, and to, databases are set up using Apache Airflow. To store the data efficiently, we created a scalable snowflake data model. We stored the data in a Relational Database Service (RDS) database on AWS. Now, everything is running on EC2 servers inside a VPC on AWS.
Please fill in your e-mail and we'll update you when we have new content!
 Check out our Meetup group!
Check out our Meetup group!