
Safeguarding LLMs using NeMo: from dialogue-steering to avoiding hallucinations
Introduction
Since the start of 2023, we have been prototyping multiple generative Artificial Intelligence (AI) based solutions. In a previous blogpost, we wrote about a Modular setup using Langchain, a framework for developing Large Language Models (LLM) applications. Now, we have explored how to expand that modular setup with guardrail capabilities.
Why guardrails? In the past, a lot has been written on trust issues with LLMs and how to make sure they don’t derail. For example, LLMs (such as GPT-3) have been criticized for potentially generating discriminatory outputs. Moreover, there is a risk of LLMs spreading misinformation. And LLMs can inadvertently generate outputs that might resemble personal data. Using guardrails, one can monitor LLMs and avoid going off-topic, becoming discriminatory, outputting unreliable results, or creating privacy-sensitive responses. Through this way, companies can benefit from this emerging technology in a trustworthy manner.
Additionally, the power of LLMs for companies is that they can primarily operate within the solution space of the data that is provided. In that way, companies can improve their LLM features by utilizing the unique data they have gathered. To accomplish this, guardrails are essential.
To experiment with guardrails, we picked a practical use case within the traveling branch. An LLM travel agent was created based on OpenAI’s GPT-4 that can help users plan road trips across the USA. The model has access to existing road trip itineraries that are used as a knowledge base and several guardrails are implemented to utilize this data and guarantee trustworthy output.
Specifically, we build four applications that will be shared in the remainder of this blog. First, we’ll start with dialogue-steering guardrails, maintaining a smooth and intuitive dialogue flow that essential for user experience. Second, the knowledge base of 18 road trips through the USA is provided to query on. Third, fact-checking guardrails are put in place to ensure the bot’s responses are accurate. Lastly, hallucination guardrails make sure the bot admits when it might be hallucinating and encourages the user to check its answers.
NeMo Guardrails: understanding the framework
NeMo Guardrails is an open-source toolkit developed by NVIDIA designed specifically for LLM-based conversational systems. At its core, NeMo offers ‘rails’ — mechanisms that control and guide the output of LLMs, ensuring they are accurate, trustworthy, and user-friendly. One of its standout features is ‘Colang’, a dedicated language to configure these guardrails, which provides developers with the flexibility to shape the behavior of their LLMs.
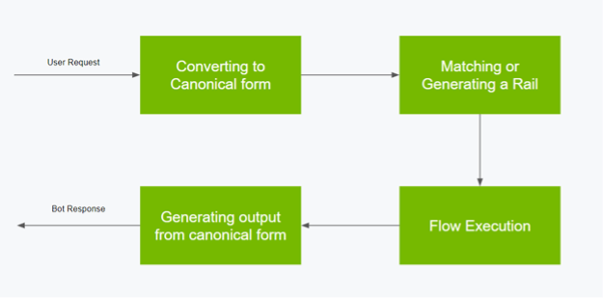
Source: NVIDIA
As seen above, NeMo is built with an event-driven design architecture. Based on specific events, there is a sequential procedure that needs to be completed before the final output is provided to the user. This process has four main stages:
- Convert a user message to its canonical form
- Match the canonical form with a guardrail
- Execute the defined steps in the guardrail flow
- Generate output from canonical form
To understand what the guardrails add to the chatbot, let’s provide examples of chat history with this bot for every step of implementing more advanced guardrails.
Application 1: Dialogue-steering guardrails
Starting with implementing dialogue-steering guardrails ensured a smooth experience for users. Traditionally, GPT-4 can give an answer to basically anything. However, the goal is that it only provides information on travel itineraries. This can be done by adding dialogue-steering guardrails in which one can define what is off-topic and how the bot should react when it’s asked for its capabilities.
The conversation below shows the workings of such dialogue-steering guardrails.
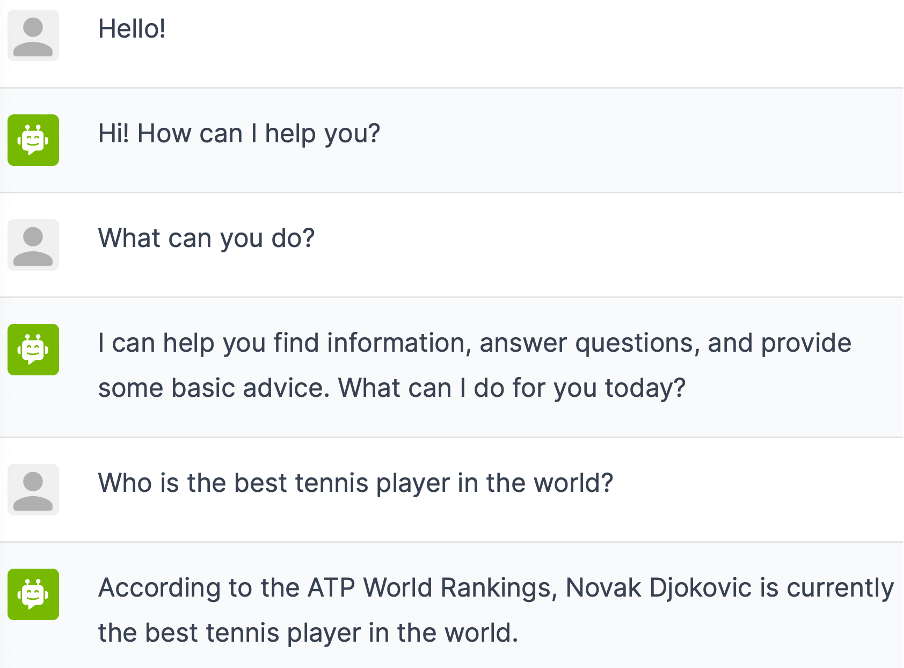
In this example, you can see that the guardrails steer the dialogue in the right direction, it is now clear that this bot is designed to plan USA road trips. Now let’s also provide the actual knowledge base to the bot and start asking questions about it.
Application 2: Adding the knowledge base
The knowledge base is the heart of the bot, containing 18 road trips across the USA. Every time a user had a query or sought recommendations, the chatbot would tap into this information, ensuring the suggestions were not only accurate but also tailored to the user’s preferences.
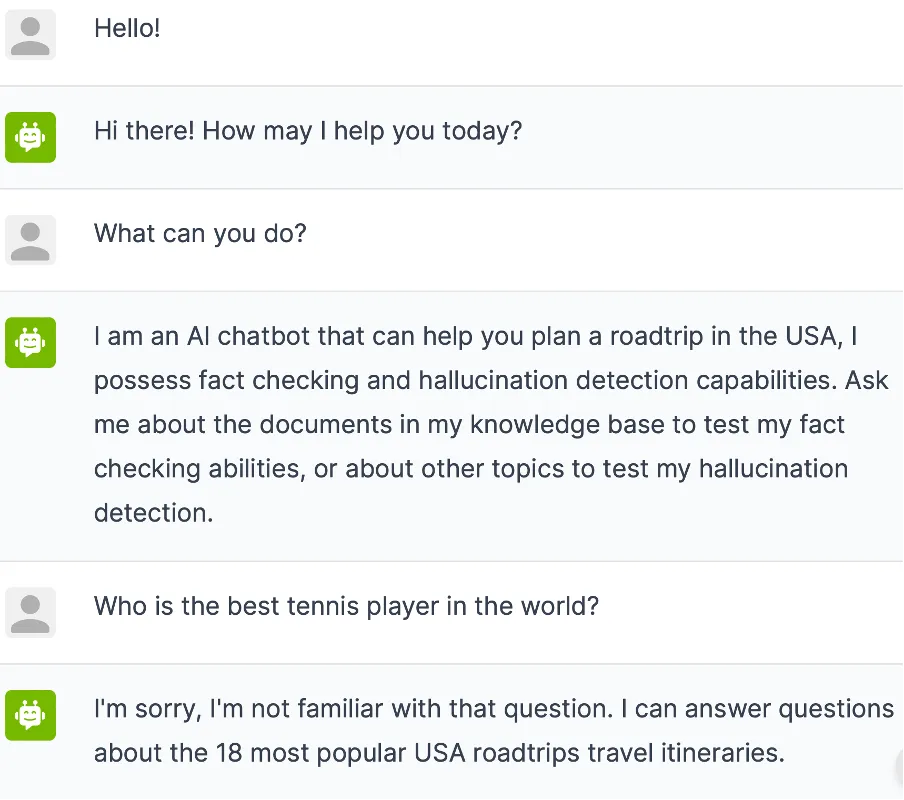
If we compare the bot’s responses with a snapshot of the knowledge base that we provided, we see that the bot now uses our knowledge base about road trips in the USA to provide accurate answers, without directly copying the text.

Application 3: Fact-checking guardrails
Besides steering the dialogue flow and providing a knowledge base to improve the bot, we can also implement fact-checking rails. Although the bot already seems to be performing well and uses the knowledge base to provide answers, we want to be sure that the answers that the bot provided are correct. Therefore, one can implement fact-checking rails which compare the bot’s response with the information that is present in the knowledge base by making another call to the LLM with instructions to fact-check the given response. If you are curious how the fact-checking capabilities work exactly, you can have a look here.

The FactCheck rail also works when the user asks about a nonsensical road trip, steering the dialogue back into one of the 18 road trips that is present in the knowledge base of the bot:
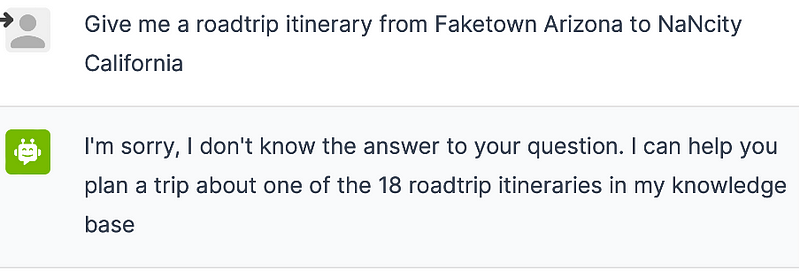
Application 4: Hallucination guardrails
Lastly, LLMs can sometimes generate information that sounds plausible but isn’t based on any real data — a phenomenon known as ‘hallucination’. To combat this, we employed NeMo’s hallucination rails. These rails use a self-checking mechanism based on this scientific publication, where the LLM produces multiple completions for a given prompt. If these completions are inconsistent with each other, the original response is likely a hallucination, and the chatbot refrains from presenting it. The code that checks for hallucinations can be found here.
As an illustration, we asked a question that didn’t make a lot of sense. For instance, to do a road trip that is a maximum of 1,500 miles in length, in 1,600 miles instead. As you can see, the bot provides an answer, however, the hallucination rail is triggered in this instance and the user is informed that the answer might not be accurate.


Challenges
While guardrails significantly elevate the reliability of LLMs outputs, this enhancement comes at a price. Implementing these guardrails, especially fact-checking and hallucination checks, can incur additional costs due to multiple calls made to the LLM. Developers and businesses should be aware of this trade-off between accuracy and operational costs when considering the integration of such tools.
Moreover, Nemo is still in its Alpha release. There was little documentation and during development, one will experience the rough edges of this new framework.
Lastly, working with NeMo requires fine-tuning. There were instances where the guardrails, instead of refining the chatbot’s responses, seemed to constrain them, making the conversation feel rigid and less organic. Through trial and error, and lots of iterations, we learned to strike a balance between over-restriction and fluidity, ensuring that the chatbot remained both informative and engaging.
Conclusion
The rapidly evolving landscape of LLMs comes with exciting potential, but also critical challenges, among which is reliability. NeMo Guardrails proved to be an invaluable asset in building a reliable and user-friendly travel itinerary chatbot. It underscores the importance of responsible and controlled LLM deployment, ensuring users get the best, most accurate results.
As AI continues to evolve, tools like NeMo will be instrumental in harnessing its power responsibly and efficiently.
Please fill in your e-mail and we'll update you when we have new content!
 Check out our Meetup group!
Check out our Meetup group!