
Recommendation Systems – An Introduction
This is part one of a three-post series on recommendation systems, where each post is dedicated to a related aspect. The series includes 1) an introduction of the fundamental concepts, 2) an investigation on how they are applied in practice and 3) an analysis on the architectural challenges.
How recommendation systems shape our online experiences
Today Recommendation Systems are ubiquitous in the online world. They are integrated into about every popular service used today, be it Google, Amazon, Netflix, Facebook, Instagram to name a few. Running at grand scale, they are possibly the largest applications currently in the Machine Learning field. We interact with them constantly, feeding these systems information about our interests and in return, they provide us with products and services to suit our needs and desires. Saving us many hours of scrolling and searching.
These systems aim to improve our online experience by serving us items, i.e. products and services, that are tailored to our personal profiles. These personal profiles are largely shaped by our online behaviour, in other words, our past interactions with items. Broadly speaking recommendation systems serve the same purpose, however, in practice, their implementation widely differs from use-case to use-case.
In this post, I will take you through the most fundamental methods used to create recommendations and consider the scenarios during which they are most appropriate. The structure will be as follows:
- Introduction of the two fundamental branches of recommendation systems, namely Collaborative Filtering and Content-based Filtering.
- Collaborative Filtering in a nutshell
- Content-based Filtering in a nutshell
Two main branches: Collaborative Filtering (CF) and Content-based Filtering (CBF)
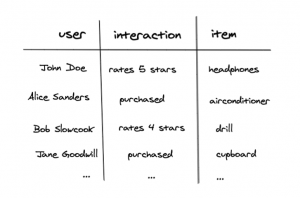
The two main methods are collaborative filtering and content-based filtering. The first utilizes the wisdom of the crowd, by only learning from the past interactions that users have made with items, it can predict what items a particular user would be interested in. The second uses the past interactions and in addition the intrinsic information of the users and/or items. One thing that the two methods have in common is that they are based on past interactions between users and items, which is typically represented in a simple table as below:
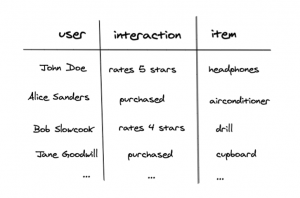
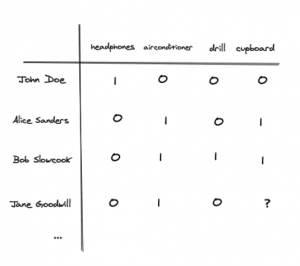
This table is further transformed into a user-item matrix where every user and item combination is represented. Here the ‘1’ signals a strong like and ‘0’ a strong dislike. The goal of these recommendation systems is, therefore, to complete this matrix by predicting the user-item interactions that have yet to occur. For example, determining the ‘?’ in the bottom left corner of the matric below, in other words, does Jane Goodwill likes cupboards?
Collaborative Filtering
Crux: make recommendations based only on past behaviour.
This method uses the past behaviour of users to identify similar users and similar items. By knowing similar users and similar items it can infer an unknown user-item interaction.
User-user CF:
Crux: recommend items that users, with similar behaviour profiles, have positively interacted with.
It can be thought of as a type of clustering, where clusters of users are made and the method recommends the consensus of the cluster that the user in question belongs to. Therefore if its cluster likes an item that the user has not interacted with then it will like it as well.
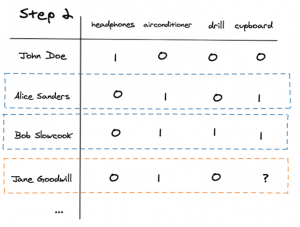
To illustrate this method we will use the user Jane Goodwill and predict if she likes cupboards. The process consists of 3 steps:
First, we identify Jane’s row of interactions.
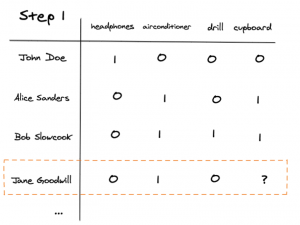
Thereafter we identify the users who have the most similar rows as Jane. In this case, Alice and Bob also interacted positively with the airconditioner and negatively with the headphones, therefore they have the most similar rows and behaviour to Jane.
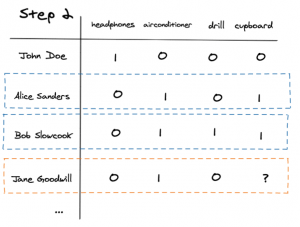
Lastly, we determine what Alice and Bob’s interaction was with the cupboard. Here Alice and Bob interacted with it favourably and therefore we can replace the question mark with a ‘1′. This changing of the ‘?’ to ‘1’ is essentially completing the matrix and predicts that Jane will indeed like a cupboard.
Item-item CF:
Crux: recommend items that are similar to the items that the user has positively interacted with.
This method, as the example above, can again be thought of as a type of clustering. Although here clusters of items are made and the method identifies the item that the user in question has a strong interest in and recommends other popular items in that item’s cluster.
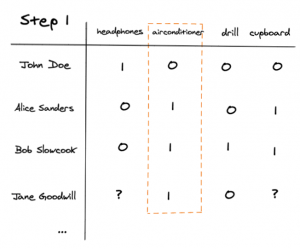
To illustrate we will again use Jane Goodwill as an example.
First, we identify the item Jane liked the most, in this case, she only liked the airconditioner.
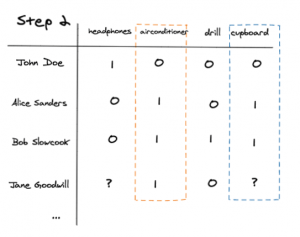
Then we compare the airconditioner’s column with the columns of other items find the most similar items.
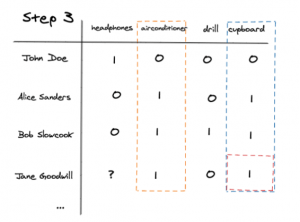
Lastly, we recommend the cupboard as this item most closely matches the column of the airconditioner.
Pros and cons
Pros
- No domain knowledge is necessary as the clustering is done automatically.
- Don’t need intrinsic information about users and items.
- The method can help to discover new items for the user.
Cons
- Doesn’t work well for a large number of items or users as In-memory CF doesn’t scale well. Performing k-Nearest Neighbours(k-NN), when calculating the clusters, has the time complexity of O(ndk) where:
- n: number of users
- d: number of items
- k: number of the considered neighbours.
Notes: Approximate Nearest Neighbours (ANN) can be used instead of k-NN. This would provide. better performance, but less accuracy.
- It suffers from the cold-start problem, in other words, it cannot make predictions on new items which the model has not trained on.
Content-based filtering
Method explained
Crux: make recommendations based on user behaviour and explicit user and or item features.
This method builds on the past user-item information and also takes into account the user’s and/or item’s features. Therefore this method usually consists out of 3 components and combines them to train a model and predict new user-item combinations. The components are as follows:
- User features, which are the intrinsic characteristics of the user, which is usually demographic data.

- Item features, which are the intrinsic characteristics of the item.
- User-item interaction data, which is used as the target variable for the model.

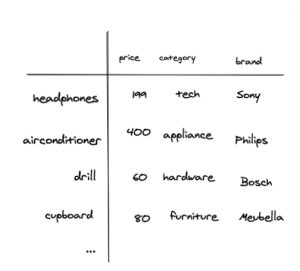
When you combine these components you create the following table. Its index consists of the user-item combination, it has an arbitrary number of user and item features and uses the user-item interaction data as the target variable:

With the above data, you are able to train a model and make predictions on specific user-item interactions.
Pros and cons
Pros:
- Doesn’t suffer that much from the cold start problem, it can make predictions on new items and users.
- The model can produce more accurate predictions than CF due to the increase in the amount of information used the recommendations can be more specific.
Cons:
- The features need to be engineered.
- In some scenarios user information very limited.
- The model’s ability to suggest new items is limited.
Conclusion
CF and CBF are the two fundamental approaches to solve recommendation problems and they come in different flavours. Each with its pros and cons, which make them suitable for different types of problems. The two main criteria that are evaluated when deciding on which method is most appropriate are the data that is available and the number of items that can be recommended. If there are plenty of rich information available about the user and the item then CBF is appropriate, else use CF. If the amount of items is large then CF will be more appropriate. There are also two-step approaches where both CBF and CF are used together to combine their strengths. To learn more about these hybrid methods and how they are applied to different use cases please see the next articles in this series: 2. How Are They Applied 3. Architectural and Latency Challenges. We take a look at different use cases and how one goes about designing and implementing these recommendation systems.
Please fill in your e-mail and we'll update you when we have new content!
 Check out our Meetup group!
Check out our Meetup group!