
Dutch scale-ups and their data teams
How many scale-ups have a data team? What are the typical roles in such a team? And when do scale-ups start investing in data? This was all included in a research that we executed on Dutch scale-ups and their data team. Find the results below!
Though the statements are objective, they also provide food for discussion. What is the reasoning behind the numbers that we see? The answers are based on my personal experience of working with many (mostly Dutch and German) scale-ups in the past 5 years. So if you think differently, let’s discuss!
Statement 1: 21% of Dutch scale-ups have in-house AI capabilities.

Discussion: How is it possible that so many scale-ups claim to be “AI-first” if only 21% of them have in-house AI capabilities?
The number of scale-ups that claim to be “AI-first” or have smart AI technology at the center of their product is rapidly growing. To find out how many of the Dutch scale-ups are truly investing in their own AI capabilities, we did not rely on claims on their websites (“our AI-powered technology”) but researched their own data & AI capabilities.
Overall, 37% of all Dutch scale-ups have a data team, with at least one data role. If we only include the more advanced ML roles (that is excluding BI and data analysts) this percentage goes down to 21%. So, in roughly 80% of the cases there is no ML engineer, AI developer, or data scientist. Though we did not check the website of these companies, I am sure that some of them claim to have an AI-driven platform or service.
It seems therefore that the “AI-driven” claim that some of them make is definitely not true in all cases. Companies use it as a marketing instrument to sell their services. They might believe in the future value of AI and just started promising it already. But the fact that they did not start building their team means that they either do not see the true value yet of having an inhouse team or that they cannot find the talent. That brings us to the second statement.
Statement 2: 63% of Dutch scale-ups do not have a single data team member.
Discussion: Are scale-ups not capable of attracting data talent?
“It is really hard to find a data scientist.” A claim that is definitely true. Data talent is scarce and when looking for more advanced roles (data engineer or machine learning engineer) this problem only grows. But is this the true reason that those companies don’t have a data team yet? I don’t think so. In my opinion these attractive, fast growing and funded scale-ups should be able to attract data talent if they are determined to do so. They can offer a challenging learning environment (broader than just tech skills), have nice offices and a vibe that is appealing to young data talent. Moreover, if talent scarcity was the problem, you would at least expect vacancies for roles at those companies. And though we did not fully investigate all of their websites on current vacancies (this might be an interesting follow-up research), it seemed that the majority did not have a data vacancy.
So my take-out is prio. Platform development, sales and marketing go above data science and especially heavier machine learning roles in the early stage of a scale-up. But when should you really start?
Statement 3: The tipping point for data science often lies around 100FTE.
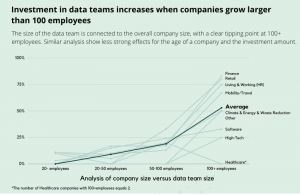
Discussion: When is the right moment to invest in your in-house data team?
It seems that once the funding rounds that allow the company to grow over a 100FTE is secured, investing in data and Machine Learning is included in the company’s roadmap. The problem that arises when starting relatively late with your data practice is often data completeness. Since no one really ever cared about using the data for future AI purposes, no one really ever cared about correct logging of the data, or logging it at all. The focus of the development team (especially in the beginning) is to keep the platform up and running, not to ensure that every detailed log which might be beneficial for future Machine Learning models is stored. Example; the webshop CEO might think that real-time and demand-based pricing is the future of his organization, but did he also tell his developers to log, timestamp and never overwrite every small price-change?
So creating early awareness of potential ML use cases is needed to ensure future value. It might be that a full-time hire is not needed yet in the early phase, but in that case get an external review to be prepared and ensure correct logging. Start to take more serious data investments around the ‘middle’ phase (50-100 FTES). These two steps will ensure shorter time-to-market of your ML solutions once you think it is truly the right moment, rather than waiting for another 2 years from that moment onwards.
Statement 4: The typical two-person data team has a data analyst and a data scientist.
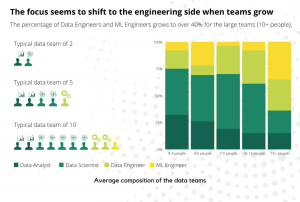
Discussion: Starting with an analyst and a scientist: a logical or risky choice?
An important question to be answered by the CTO is what will be my first data hire? Looking at the data, we found that a typical two-person data team consists out of one data analyst and one data scientist. At first glance, this kind of makes sense. Especially the data analyst role; when the data pile grows the number of requests about the data from the business grow and hence a data analyst is often the first role that is hired to deliver to these requests. But rather than a data scientist next to him a data engineer would be a more complementary role in the early stage. The engineer can assure that data pipelines are constructed, avoiding the analyst of doing repetitive analyses over and over again. This way future value for the scale-up is ensured. Once the analyst created dashboards on top of these pipelines the step towards machine learning and hiring a data scientist can be made.
Statement 5: 10% of the data teams only have one data scientist.
Discussion: Is the one-person data science army the ideal way to start your data investment?
So what is the biggest pitfall or ‘mistake’ when it comes to building your data capabilities? That’s probably starting with a team with only one junior data scientist. 10% of the companies with a data team followed this strategy in our sample. Though there might be exceptions, the following is likely to happen: the data scientist does not want to execute too much work that is thought off as ad-hoc analytics or even dashboarding. What they like the most is creating predictive models. But can you expect from a junior data scientist that they know which use case (model) to select after an ease/impact study and how to technically integrate this into the product of process? Unfortunately, the answer is often no. Meaning that the data science either ends up doing the analytics anyway (and hence leaves the organization looking for a more sciency job), or ends up spending expensive time on models which end up on the famous “data science graveyard”.
The best way to do it? Either start with an external partner or start with a data analyst for 6-12 months just to get things started and explore first value. Soon after that when you want to takes things more serious, work towards a three-person team: head of data, data engineer, data analyst. Once the architecture is there, BI is neatly in place and data can be trusted, hire your data scientist and start development of ML models.
Statement 6: E-commerce, Finance and Software/Saas are taking the lead when it comes to having an internal data team.
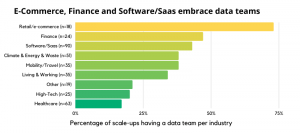
Discussion: Why do high-tech and healthcare companies invest less in data teams than other industries?
Data grows exponentially when your companies customer base grows: more customers means more transactions means more different products means more interactions. This holds true for the majority of e-commerce, finance and SaaS companies. Even in a relatively early stage of these companies there is a need to have deep insights in KPIs related to this and hence a data analyst is often hired. Multiple arguments play a role here. First of all, the high-tech and healthcare scale-ups are more often B2B focused. The number of customers and products is smaller, so from a marketing perspective there is less of a direct need for a data analyst or data scientist. Second, especially healthcare is a highly regulated market, so challenges of building but especially adopting AI solutions and relying on their outcomes are fiercer.
Please fill in your e-mail and we'll update you when we have new content!
 Check out our Meetup group!
Check out our Meetup group!